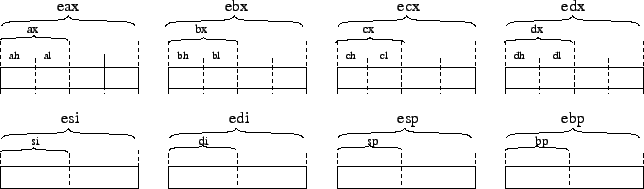
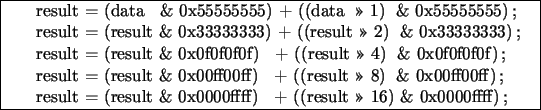Le découpage des registres du processeur en 4, 8, 16 et 32 bits permet d'assurer une compatibilité binaire entre le P4 et les anciens processeurs de la famille x86 comme le 80286, 80386, 80486,... qui eux sont construits sur 4, 8 ou 16 bits.
Le Pentium IV permet d'effectuer les opérations arithmétiques élémentaires sur des
entiers de 32 bits comme: le xor ![]() , le ET logique
, le ET logique ![]() , le ou
inclusif
, le ou
inclusif ![]() , le décalage vers la droite », le décalage vers la gauche «, l'addition
+, la multiplication *, le modulo % et la division /.
, le décalage vers la droite », le décalage vers la gauche «, l'addition
+, la multiplication *, le modulo % et la division /.
Options d'optimisation:
Notre projet a été développé sous Linux (2.6.11-6mdk) et compilé avec
gcc (3.4.3) et avec les options d'optimisation suivantes:
Nous avons généré deux fois le code assembleur de cette fonction sur un Pentium IV, la première fois sans utiliser les options d'optimisation présentées précédemment et la deuxième fois en utilisant ces options. Nous présentons sur les deux figures qui suivent quelques lignes de chacun des fichiers assembleurs correspondants:
1 pushl %ebp
2 movl %esp, %ebp
3 subl $4, %esp
4 movl 8(%ebp), %edx
5 andl $1431655765, %edx
6 movl 8(%ebp), %eax
7 shrl %eax
8 andl $1431655765, %eax
9 leal (%edx,%eax), %eax
10 movl %eax, -4(%ebp)
11 movl -4(%ebp), %edx
12 andl $858993459, %edx
13 movl -4(%ebp), %eax
14 shrl $2, %eax
15 andl $858993459, %eax
|
1 pushl %ebp
2 movl %esp, %ebp
3 movl 8(%ebp), %edx
4 popl %ebp
5 movl %edx, %eax
6 shrl %edx
7 andl $1431655765, %edx
8 andl $1431655765, %eax
9 addl %edx, %eax
10 movl %eax, %ecx
11 shrl $2, %eax
12 andl $858993459, %eax
13 andl $858993459, %ecx
14 addl %eax, %ecx
15 movl %ecx, %eax
|
En comparant les deux figures, on remarque que les options
d'optimisation utilisées changent le code en supprimant des
instructions, par exemple la ligne 3 de la figure ![]() n'existe
pas dans la figure
n'existe
pas dans la figure ![]() ou encore en changeant l'ordre
d'exécution de quelques instructions. D'autres optimisations sont
faites en utilisant mieux les registres du processeur: sur la figure
ou encore en changeant l'ordre
d'exécution de quelques instructions. D'autres optimisations sont
faites en utilisant mieux les registres du processeur: sur la figure
![]() on se sert uniquement de eax et de edx alors que sur la figure
on se sert uniquement de eax et de edx alors que sur la figure
![]() , on se sert en plus de ecx. Une autre optimisation consiste
à réduire le nombre d'indexation et de décalage en mémoire, par
exemple 8(%ebp), on en compte six opérations de ce type dans le code
non optimisé contre seulement une seule dans le code optimisé.
, on se sert en plus de ecx. Une autre optimisation consiste
à réduire le nombre d'indexation et de décalage en mémoire, par
exemple 8(%ebp), on en compte six opérations de ce type dans le code
non optimisé contre seulement une seule dans le code optimisé.
Ces options ont été utilisées lors du développement du chiffrement DECIM et elles ont permis d'améliorer les performances de DECIM en diminuant le nombre de cycles CPU lors de son exécution.