



suivant: LFSR: Linear Feedback Shift
monter: Implémentation de l'ABSG
précédent: Deux cas d'implémentation possibles
Table des matières
Nous avons comparé les méthodes présentées précédemment sur un Pentium
4. Le schéma ![[*]](file:/usr/lib/latex2html/icons/crossref.png) présente le nombre de cycles
CPU pour chaque implémentation en fonction des mots binaires.
présente le nombre de cycles
CPU pour chaque implémentation en fonction des mots binaires.
Les tests ont été effectués sur des mots binaires générés aléatoirement avec la fonction
rand().
Figure:
Nombre de cycles CPU pour chaque méthode en fonction de la taille des
mots binaires.
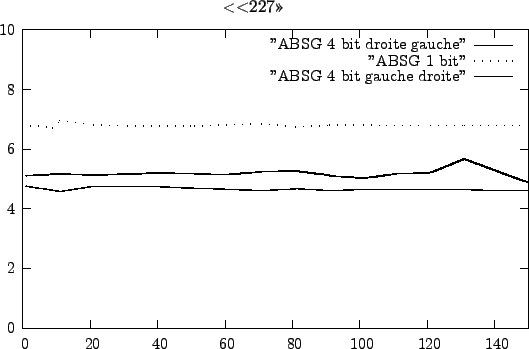 |
Nous avons réussi grâce à des mises en tables à augmenter la vitesse de
l'ABSG pour un coût modeste grâce à des tables de 80 octets. La
meilleure méthode est donc celle traitant les bits par 4 de la droite
vers la gauche. Elle a donc été choisie pour l'implémentation finale de DECIM.
RIDENE YOUSSEF
2005-09-05